
Bin-fullness estimation (BFE) in waste management is a specialized area with limited research.
In this post, we will focus on comparing the BFE capabilities of Generative AI (GenAI) models versus traditional AI, specifically Zabble’s in house computer vision AI models. The GenAI models evaluated were ChatGPT-4o (OpenAI), Gemini Flash 2.0 (Google), and Claude Sonnet 3.7 (Anthropic).
Fullness prediction is a key component of Zabble’s computer vision AI stack. We currently run two specialized models—one for indoor settings, one for outdoors—so each can perform at its best in the conditions it was built for.
Data Gathering
To teach AI about bin fullness, human annotators manually label photos with their best guess. But photos are flat, and bins are not, so some depth and perspective is always lost in translation.
The more precise we need the AI to be, the bigger this problem becomes. Clients have told us that precision matters, as better granularity means better insights. Judging how full a bin is can be subjective—two people can look at the same photo and see it differently. It is easier to estimate bins that are closer to empty or full than in the middle. For example, a bin that looks 40% full to one person may look 50% full to another. That makes bin fullness inherently difficult to measure accurately.
AI and GenAI models are only as good as the data on which they’re trained. If the data is noisy or inconsistent, the model will inherit those flaws. With the rise of GenAI models and the growing trend of using them in a zero-shot manner (with no problem-specific training), we became curious. Given what we know about the challenges of BFE, how well can a GenAI model estimate bin fullness with no prior knowledge of the task?
Methods
To interpret the results of our study, it’s important to understand the fullness dataset we use at Zabble. Our labels are structured into ranges, such as fullness between 20-35% or fullness between 35-45%. When annotators are uncertain, they may select multiple ranges to reflect a broader estimate (e.g. 20-45%).
Our test dataset includes 1,039 indoor images and 3,593 outdoor images. The indoor set is relatively small. For this reason, we focus this evaluation on our outdoor fullness model compared to GenAI models.
Results
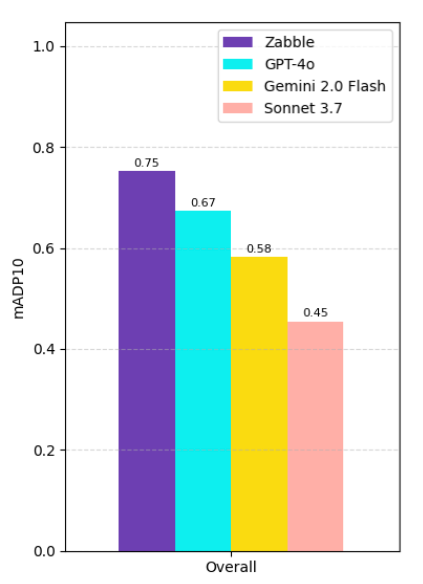
Zabble consistently outperformed all GenAI models in BFE. To create a standardized evaluation metric, Zabble used a derivative of the mean adjacent differential precision (or mAP) metric called the mADP10 to evaluate bin fullness results across all the models within 10% of the annotated values.
Zabble’s bin fullness model achieved an mADP10 of 75%, which means that the model predicted bin fullness within 10% of the actual fullness with a 75% accuracy. This outcome is not unexpected, as the inherent uncertainty in estimating bin fullness requires both human and AI systems to align with real-world likelihoods, something that is difficult to achieve with generic, off-the-shelf GenAI models.
For bin-fullness estimation, traditional computer vision AI remains a superior solution, provided that it is trained with proper uncertainty quantification methods. At Zabble, we continue to invest in research to improve this approach.
Learn more and schedule a demo of Zabble’s AI here.
Our Latest Blog Posts
Curbing Contamination: Lessons from an EPA-Funded Regional Cart Tagging Initiative
Zabble recently hosted a webinar with the US EPA, Hampton Roads Planning District Commission, The Recycling Partnership and York County, Virginia.
Thursday, May 14, 2026
How AI Makes Contamination Monitoring Scalable
For decades, waste programs have relied on annual audits, spot checks, and hauler reports to understand contamination. While these methods provide occasional snapshots, they leave significant gaps in understanding when, where, and why contamination occurs.
Friday, January 9, 2026
What Oregon Cities and Counties Need to Know About Recycling Modernization Act (RMA) EPR Compliance
For Oregon jurisdictions, the challenge is clear: how do you effectively track contamination, implement targeted interventions, and prove program effectiveness to access PRO funding—all while managing the day-to-day demands of waste operations?
Monday, December 1, 2025
ADDRESS
1966 Tice Valley Blvd, #105,
Walnut Creek, CA 94595
CONTACT
Tel.: 925-289-9345
Email: team@zabbleinc.com

Mobile Tagging
U.S. Patent No. 11,788,877
Social Icons
